Finding the Hardest Spelling Bee Puzzle
An Unnecessarily Detailed Analysis of Word Puzzles From The New York Times
March, 2022
The Spelling Bee is a word puzzle published daily by The New York Times. Despite the name, it has nothing to do with those competitions where contestants compete to spell obscure words. Instead, the goal is to list as many words as possible using only a given set of letters, along with some other restrictions. The rules are so simple that the game sounds trivial, but it isn't (at least for us humans). This got me thinking about mathematically modeling difficulty in Spelling Bee puzzles, which led me down the rabbit hole of exploring the space of all possible Spelling Bee puzzles, and how the puzzles published by The New York Times fit into that space. Along the way, I found the easiest and hardest possible puzzles (as well as the easiest and hardest that The New York Times has ever published), and lots of other results in this unnecessarily detailed analysis of the Spelling Bee.
Source notebook available here.
Contents
- 1 The Rules of the Game
- 2 Quantifying Difficulty
- 2.1 How Humans Solve Spelling Bee Puzzles
- 2.2 Word Probability
- 2.3 Word Difficulty
- 2.4 Puzzle Difficulty
- 3 Finding the Hardest (and Easiest) Bee
- 3.1 First Attempt
- 3.2 Relationship Between Difficulty and the Number of Solutions
- 3.3 The 25 Easiest Puzzles
- 3.4 The 25 Hardest Puzzles
- 4 How Do the Published Puzzles Fit Into the Space of All Puzzles?
- 4.1 Validating the Word List
- 4.2 Hardest and Easiest Published Puzzles
- 4.3 Difficulty of Published Puzzles
- 4.4 Number of Solutions for Published Puzzles
- 5 Future Directions
- 6 Fun Stats
The Rules of the Game
For each puzzle, the player is presented a hexagon of letters like this:

The goal is to list as many words as possible that meet the following criteria:
- The word uses only the letters in the hexagons (in this case, "M", "A", "G", "L", "O", "R", and "U").
- The word contains the center letter (in this case, "M").
- The word is at least four letters long.
- The word is not "obscure", offensive, or a proper noun.
For example, "grammar" is a valid solution for the puzzle above. However, "aura" is not a valid solution because it does not contain "M".
The puzzle itself must satisfy the following criteria:
- There must be at least one "pangram": a word which uses all of the letters. In this case, the pangram is "glamour".
- It cannot contain the letter "S" (because it would be too easy to form plurals).
Scoring works by the following rules:
- Four letter words are worth one point.
- Words with \(n>4\) letters are worth \(n\) points.
- Pangrams of length \(n\) are worth \(n+7\) points.
The objective is to get the highest possible score. As such, there is no fixed score required to "win", but there are ranks which are assigned based on the score. The highest rank is "Genius", which requires that the player get at least 70% of the available points.
Quantifying Difficulty
The first step in this project was quantifying difficulty. What makes some puzzles hard and others easy? For computers, these puzzles are all easy. This Mathematica program can (approximately) solve them in 141 characters:


So what makes these hard for humans? To answer this question, we need a model of human solvers from which we can derive a measure of difficulty.
How Humans Solve Spelling Bee Puzzles
I can't speak for other people, but here is how I think about these puzzles.
Let's take the puzzle above as an example. I start by picking a popular-seeming first letter. In this case, "G" seems like a good place to start. Next, I think about what letters might come after "G". "M" doesn't seem very likely (do you know any words that start with "GM"?) but "R" could work. Now, what letters might come after "GR"? In this case, I could try "O", resulting in the candidate "GRO", etc. Repeating this process, I either hit a word (like "GROOM") or I give up (after reaching something which isn't a word like "GROMULAR").
This process is a bit like a Markov chain. Given some candidate like "GROO", the model player looks at the last few characters and randomly picks the next letter based on the frequency of the resulting n-gram in English. For example, appending another "O" would result in the "OOO" 3-gram, which is not very common, but appending an "M" results in the much more common "OOM" 3-gram, so the model player would be much more likely to add an "M" than an "O".
I'm sure others players use different strategies, and I'm sure I don't always follow this strategy either. However, this is a natural algorithm that approximates a large part of the thought process. It is also easy to analyze mathematically, so I used it to construct the measure of puzzle difficulty.
Word Probability
Using this model, let's compute the probability that a player would guess the word "GROOM". For simplicity, we'll set \(n=2\). First, because about 2% of English words start with "G", the model player has a 2% chance of starting its guess with a "G". (Among other things, this ignores the fact that in the real puzzle, there are only seven choices of first letter instead of 26. The code deals with that, but I'm going to ignore it for this example.)
Then, because 12% of "G"s in English are followed by an "R", there is a 12% chance that the next letter of the guess is an "R". Continuing, given that the previous letter was an "R", there is an 11% chance that the next letter is an "O", etc. The probability that the model player guesses "GROOM" is the product of these probabilities.
This is just a Markov chain. Writing this more formally, let \(N(\alpha\beta)\) denote the probability that the next letter of the guess is a \(\beta\) given that the last letter was an\(\alpha\), and let \(S(\epsilon)\) denote the probability that the first letter of the guess is \(\epsilon\). The probability of guessing "GROOM" is given by $$S(\text{G}) \cdot N(\text{GR}) \cdot N(\text{RO}) \cdot N(\text{OO}) \cdot N(\text{OM}) = 0.02 \cdot 0.12 \cdot 0.11 \cdot 0.02 \cdot 0.06 \approx 10^{-7}$$ Let's call this product the word probability, and \(N\) the n-gram probability. Word probability was the first (and most naive) measure of word difficulty that I considered.
Computing the word probability is simple, and the only outside data that's needed is the frequencies of n-grams in English, which can be generated from this dataset. In most of the examples below, I use \(n=2\), but any \(n\) would work. (There are some details about how the n-gram probabilities need to be normalized from puzzle to puzzle, but they are not important to the overall system here.)
To take an example, the word probability of "GROOM" is about \(10^{-7}\), while the word probability of "QUEUE" closer to \(10^{-8}\), indicating that a model human player would be more likely to guess "GROOM" than "QUEUE".
I computed the word probability for every word in my word list (ignoring some normalization), giving these as the ten most and least probable:
| Highest probability | Lowest probability |
|---|---|
| then | blowzier |
| thin | blowziest |
| than | blowzy |
| there | frowzier |
| that | frowziest |
| here | frowzy |
| thee | magnetohydrodynamics |
| them | electroencephalographs |
| this | electroencephalographic |
| tint | straightforwardnesses |
This reveals a major problem with using word probability to measure the difficulty of guessing an individual word: it heavily penalizes longer words. You can see in the table above that the highest probability words are almost all four letters long, while the lowest probability ones are absurdly long. For example, the word probability of "GROOM" is about \(10^{-7}\), but the word probability of the plural "GROOMS" is only about \(10^{-8}\), indicating that "GROOMS" is significantly harder to guess than "GROOM", which seems wrong.
The problem is that every additional letter corresponds to an additional n-gram probability in the product used to compute word probability, and n-gram probabilities are always very small. In this case, the word probability of "GROOMS" equals the word probability of "GROOM" multiplied by the probability that an "M" is followed by an "S" in English, which is on the order of \(10^{-2}\).
If word probability is to measure the difficulty of guessing a word, it needs to be modified to be less sensitive to word length.
Word Difficulty
By rewriting the formula for the word probability, it is possible to create a related metric which shares much of the same intuition, but which is less sensitive to word length.
The word probability of "GROOM" was given by a product of n-gram probabilities. For the sake of simplicity, let \(f_i\) represent the \(i\)th term of that product, $$\begin{align} f_1 &= S(\text{G}) \\ f_2 &= N(\text{GR}) \\ f_3 &= N(\text{RO}) \\ f_4 &= N(\text{OO}) \\ f_5 &= N(\text{OM}) \end{align}$$ so the word probability \(p\) can be written as $$\begin{align} p &= S(\text{G}) \cdot N(\text{GR}) \cdot N(\text{RO}) \cdot N(\text{OO}) \cdot N(\text{OM}) \\ &= f_1 f_2 f_3 f_4 f_5 \end{align}$$ More generally, the word probability of an arbitrary word can be written as the product $$p = f_1f_2 \dots f_m$$
With some borderline trivial algebra, we can rewrite this equation as $$p = f_ 1f_ 2\dots f_m = (\sqrt[m]{f_ 1f_ 2\dots f_m})^m$$ where \(\sqrt[m]{f_ 1f_ 2\dots f_m}\) is the geometric mean of the n-gram probabilities. Written this way, it is easy to separate the word probability into a base term which does not vary with word length (\(\sqrt[m]{f_1f_2\dots f_m}\)) and an exponent term which incorporates the word length (\(m\)). By this logic, we can "remove" sensitivity to word length by removing the exponent term and using the geometric mean of n-gram probabilities as the metric for word difficulty. Let's call this quantity \(g\).
Not only is \(g\) justified by its relationship to word probability, but it also has its own convergent justifications. By the same intuition that motivated word probability, it makes sense that the difficulty of guessing a particular word is the "average" difficulty of its n-grams. It might seem strange to compute the "average" using the geometric mean instead of the arithmetic mean (or the the median). However, the geometric mean has several advantages over other averages independent of its relationship to word probability. In particular, the geometric mean behaves well with normalized values, and with values that span multiple orders of magnitude, both of which describe n-gram probabilities from natural languages.
However, it might be good for word length to have some effect, even if it is smaller than the effect it has on word probability. Instead of raising \(g\) to the power \(m\) (which gives the word probability), we can raise it to some smaller number which varies with \(m\). In particular, if we let \(\alpha\) be a parameter representing the desired sensitivity to word length, then $$g^{a(m-1)+1} = \left(\sqrt[m]{f_ 1f_ 2\dots f_m}\right)^{a(m-1)+1}$$ gives \(g\) when \(\alpha = 0\) and the word probability \(p\) when \(\alpha = 1\) making \(\alpha\) a good parameter for specifying the importance of word length. Finally, I added a small dampening term \(\beta\) to the n-gram probabilities so that rare n-grams are not penalized too harshly $$\left(\sqrt[m]{(f_ 1+\beta)(f_ 2+\beta)\dots (f_m+\beta)}\right)^{a(m-1)+1}$$ (This dampening term is actually analogous to the random jump probability in the PageRank algorithm.) Let's call this measure the word difficulty.
In summary, we can model the difficulty of guessing an individual word by the geometric mean of the normalized, dampened frequencies (in English) of its n-grams, optionally raised to a small power so that longer words are considered more difficult than shorter ones.
(Note: Lower word difficulty means harder to guess. This is a bit confusing, but I'm not sure what else to call word difficulty which would be clearer.)
With this system, "GROOM" has a word difficulty of about \(3.1 \cdot 10^{-3}\) while "GROOMS" has a word difficulty of about \(2.4 \cdot 10^{-3}\), which are pretty similar (unlike the results we saw with word probability).
As with word probability, I computed the top ten easiest and hardest words by this new measure:
| Easiest | Hardest |
|---|---|
| then | blowzier |
| there | blowziest |
| thin | blowzy |
| than | frowzier |
| that | frowziest |
| these | frowzy |
| here | kudzu |
| thee | snuffbox |
| them | kohl |
| tithe | kudzus |
Puzzle Difficulty
The next step is to use our measure of word difficulty to develop a measure of puzzle difficulty. The overall approach will be to find all words which are solutions to a given puzzle, and to aggregate their word difficulties in some way.
The virtue of modeling puzzle difficulty by aggregating the difficulties of the solution words is that it lets us take into account the distribution of word difficulties. For example, if a puzzle has a hundred trivial words, but the player must guess at least one incredibly hard word in order to reach the score required for the Genius rank, then this puzzle should be considered difficult. On the other hand, if a puzzle has dozens of difficult words as solutions, but the player can reach Genius rank without them, then the puzzle should not be considered difficult.
(I should note that there are two broad ways in which puzzles could be judged: by the expected score the player will reach, or by the probability that they reach the score required for Genius rank. I think that the first method is not actually well defined, because the irregular spacing of word difficulties can lead to the expected score varying with player ability in complicated, nonlinear ways that will be different from puzzle to puzzle. For that reason, I will generally be looking at the probability of reaching Genius.)
By this analysis, I argue that puzzle difficulty should be judged by the difficulty of the hardest word which the player must guess in order to reach Genius. The score required to reach Genius equals 70% of the total number of points available, so we can calculate puzzle difficulty by the 30% quantile of the difficulties of solution words weighted by their scores. (It's the 30% quantile instead of the 70% quantile because lower word difficulty corresponds to harder words.) This measure has the advantage that it is a bit like taking the "average" of the solution word difficulties, but it also takes into account the score threshold for Genius. Let's call this measure the puzzle difficulty.
Finding the Hardest (and Easiest) Bee
Every puzzle must have at least one solution which uses all seven of the letters (the pangram). It turns out there are only about 17000 words which contain exactly seven unique letters, and only about 6500 that also don't contain "S", so the number of possible puzzles can't be more than \(7*6500=45500\) (because there are seven choices for the center letter). In fact, a bit of redundancy means that there are only about 30000 puzzles. This number is small enough that it can be explored by brute force.
First Attempt
After computing the difficulties of all legal puzzles, these are the 25 easiest (note the horizontal scroll bars):

And these are the 25 hardest legal puzzles:

(The words below each puzzle are the valid solutions. Bold words are pangrams, and red words are those which are harder than the hardest required word, so they don't affect the difficulty rating of the puzzle. Also, note the horizontal scroll bars.)
Some of these are more convincing than others, but the most suspicious feature of these puzzles as a group is that they have so few solutions. In fact, they have so few solutions I question whether many of them should be considered valid puzzles at all.
Relationship Between Difficulty and the Number of Solutions
Why do these puzzles have so few solutions? Perhaps most puzzles only have a few solutions, and the puzzles published by The New York Times have been specially selected to have an anomalously large number of solutions? It turns out, no, this is not the case, as this histogram shows:

Most puzzles have dozens of solutions, and far more than the easiest and hardest puzzles above. To understand why the extreme puzzles have so few solutions, it helps to look at the distribution of all puzzle difficulties:

In particular, note that puzzle difficulties appear to be approximately normally distributed. This isn't surprising because puzzle difficulty is computed as an average of averages, so it should obey the central limit theorem, and adding more terms to that average (by having more solutions) leads to regression to the mean. This explains why the examples above, which are at the extreme tails of that distribution, have very few solutions.
As predicted, by plotting the difficulty as a function of the number of solutions, you can see how puzzles with more solutions have difficulty closer to the average than puzzles with fewer solutions:
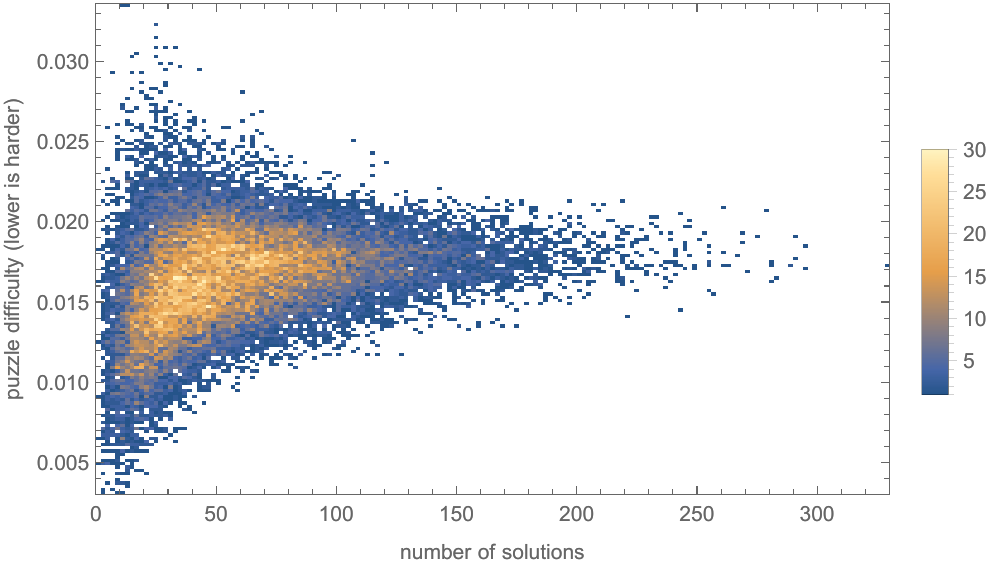
In any case, this means that the easiest and hardest puzzles are likely to have very few solutions. The simplest way to find more realistic puzzles is to filter out puzzles which have fewer solutions than some threshold. But how can we pick the threshold?
As far as I can tell, there is no published rule which restricts the minimum number of solutions. However, I've acquired archives of past puzzles published by The New York Times, and looking at these reveals a hard cutoff at 21 solutions:

The 25 Easiest Puzzles
With this, I removed all the puzzles with fewer than 21 solutions, leaving these as the 25 easiest:

With this new restriction, the three of the top five easiest puzzles all have the same pangram "flinching", and are only differentiated by the choice of center letter!
Otherwise, the most striking pattern is that all but a few contain the letters "ING". Common endings like "ing" make it easy to write lots of high-scoring words by extending shorter words (like "inch" to "inching").
I also noticed that these mostly contain common letters, especially in the center slot. A few puzzles (like these below) deviate from this pattern in an interesting way:

(These have fewer than 21 solutions, but are otherwise some of the easiest puzzles overall.)
These easy puzzles are unusual for containing letters like "Z" and "V". However, in the first puzzle, only two solutions use "Z" ("kibitz" and "kibitzing"), and neither are required to reach Genius (and consequently don't affect the difficulty rating of the puzzle). In principle, any letter could be used instead of "Z", but a more common letter would introduce lots of new solutions, significantly increasing the score required for Genius. The only function that "Z" serves is to take up a slot while minimally increasing the number of solutions, with "V" playing a similar role in the second puzzle. Earlier, we saw how extremely easy and extremely hard puzzles generally have fewer solutions due to regression to the mean, so it makes sense that a puzzle can be made easier by using a "burner letter" which keeps the solution count low.
The 25 Hardest Puzzles
Next, these are the 25 hardest puzzles with at least 21 solutions:

I don't have much to say about these, other than that they contain more exotic letters like "X" and "Q" when compared with the easiest puzzles.
How Do the Published Puzzles Fit Into the Space of All Puzzles?
As I mentioned earlier, I have the records of the puzzles that were actually published by The New York Times, so we can look at how those puzzles compare with the space of all possible puzzles.
Validating the Word List
The first step was computing the difficulties of all of the published puzzles. However, some issues arose from the way that The New York Times generates its solution lists.
Up to this point, given a puzzle, I computed the list of valid solutions by looking at a big list of words, and selecting those which met the criteria for valid solutions. However, The New York Times doesn't do it this way. Instead, the solution list for each puzzle is curated by a human, often in inconsistent ways. For example, there are words which were accepted as solutions in one puzzle, but were deemed too obscure to be solutions for a later puzzle, and vice versa. This makes it impossible to construct a single word list which perfectly reflects how The New York Times does it.
To illustrate, this puzzle was published twice with two different word lists (differences shown in blue):

Most of the puzzles which I looked at in the previous sections have never been selected for publication by The New York Times, so there is no way of knowing what word list they would have used. I am only able to approximate solution lists, but now I have the real solution lists for the subset of puzzles that were published.
Before anything else, I wanted to verify that the synthetic solution lists that I have been generating give similar results to the real solution lists, at least on those puzzles where I have access to the real solution lists. This plot compares the puzzle difficulty score when computed with the synthetic solution lists, versus when computed with the real solution lists:

If every point were on the diagonal line, then the synthetic solutions list would perfectly emulate the real solution lists. Because it is only an approximation, some points do not lie exactly on the line. However, there does not appear to be a systematic bias, and the synthetic data generally matches the real data, suggesting that the synthetic solution lists are very similar to the real solution lists (at least for the purposes of computing puzzle difficulty).
The histogram below compares the distribution of difficulties using the real and synthetic solution lists:

The histograms are quite similar, again showing that the synthetic solution lists are a good approximation of the real solution lists.
Most of my earlier results were computed with synthetic word lists, so the fact that the real word lists gave similar results (in the cases were real word lists were available) helps verify those earlier results. For the sake of consistency, I will still use synthetic solution lists for both published and unpublished puzzles when comparing them, but I will sometimes use the real solution lists in cases where no such comparisons are being made.
Hardest and Easiest Published Puzzles
With that out of the way, these are the 25 easiest published puzzles:

And these are the 25 hardest:

It's nice to see that the easiest possible puzzle was published on October 2nd, 2021. It would be great to see the stats on how many players reached Genius on that date.
Difficulty of Published Puzzles
My next question was: were the published puzzles specifically selected for their difficulty? Are they significantly easier or harder than randomly selected puzzles? To test this, the histogram below shows the distribution of difficulties of published puzzles versus all puzzles:

The histograms are a bit noisy, but it does look like the published puzzles were generally harder than the legal ones, suggesting that The New York Times selected puzzles for their difficulty. Looking at puzzle difficulty over time, however, shows no particular trends:

I also wanted to check whether difficulty varies by day of the week, as it does for the crossword puzzles. However, the smooth histograms of puzzle difficulty for each day of the week also show no particular trends:

Number of Solutions for Published Puzzles
In addition to being selected for difficulty, published puzzles appear to have been selected for their number of solutions. The histogram below shows the distribution of the number of solutions for all legal puzzles vs published puzzles:

While legal puzzles often have 100 or more solutions, those which were published usually have far fewer. Looking at the number of solutions in published puzzles over time also shows a mysterious jump around August of 2020:

I can't find any information about changes to the editorial process from that period, but it looks like something must have happened. If anyone has any information about this, please contact me!
Future Directions
There are a few directions for future work, most having to do with improvements to the measure of puzzle difficulty. I chose the measure I did because it has a nice mathematical justification which follows from how I personally solve Spelling Bee puzzles. However, other people probably use different strategies, and so this measure will not reflect their experience as well. There are also some things which the current measure doesn't take into account, such as how similar solutions (like "flinch" and "flinching") shouldn't really be counted as separate because the probably of guessing them is not independent.
Fun Stats
In working on this project, I computed lots of things which don't fit nicely into the broader narrative, but which are interesting or amusing on their own. This section contains a selection of those computations
Influence of Center Letter Choice
For every pangram, there are 7 associated puzzles, each formed by choosing a different center letter. The question is, how does the choice of center letter affect difficulty?
For every pangram, I computed the difficulties of the associated puzzles for each choice of center letter. I then computed the difference between the difficulty with _ as the center letter when compared with the mean difficulty of all 7 choices of center letter. Averaging those results together for all pangrams gives the plot below:

This shows that choosing center letters like "B", "J", "K", "X" or "Z" generally makes the puzzle more difficult, while center letters like "V","N", and "E" make the puzzles easier. If you want to design a difficult puzzle given a pangram, you could use this chart to pick the center letter.
Most Common Solutions
These are the most common solutions among all legal puzzles, along with the fraction of puzzles containing each word:

And these are the most common among puzzles published by The New York Times:

Unsurprisingly, words that only contain two or three unique letters are the most common solutions.
Puzzles With the Most Solutions
These are the published puzzles with the most solutions, with a max of 81 solutions:

However, if we include all legal puzzles, then there are puzzles with hundreds of solutions. Here are the top five, with a max of 329 solutions:

I like how some of these have tons of pangrams, while others have just one.
Highest Scoring Puzzles
These are the published puzzles with the highest possible scores. The top one has a max score of 537:

Though 537 seems high, it is only because published puzzles have been filtered to have a relatively small number of solutions. Among all legal puzzles there are some much higher scorers. In particular, it is possible to get 2061 points on the top scorer, with dozens of pangrams. Here it is, along with the other top five:

Average Points per Solution
This is the distribution of the number of points awarded for each solution (using the solution lists from published puzzles):

There are a lot of four letter solutions, which are all worth one point. Then, there are the normal solutions, which are each worth at least five points (because they must be at least five letters long). Then, there are the pangrams, which are each worth at least 14 points (because they must be at least seven letters long, and the seven is added to their score for being pangrams).
Looking at the same distribution for all puzzles (including unpublished ones) is similar, but generally contains higher scoring words:

Puzzles With the Most Pangrams
Most puzzles (both published and unpublished) only have a single pangram:

However, some have more, such as this puzzle published on December 16th, 2021 which has eight pangrams:

Among all puzzles (including unpublished ones), those with the letters "A", "E", "G", "I", "N", "R", and "T" have the most pangrams, with 26. The choice of center letter does not matter because pangrams have to include all of the letters anyway. You can see examples of these puzzles above, as they are also some of the highest scoring ones. (Just find one with the top pangram is "reintegrating".)
Letter Choice
My next question was: what letters does The New York Times gravitate toward? For example, do published puzzles tend to use "A" more than would be expected by chance?
The plot below shows the frequency with which letters appear in all possible puzzles vs the frequencies with which they appear in the published puzzles:

This shows that some common letters like "E" and "R" are underrepresented, while some others like "Y" and overrepresented. However, it is hard for me to tell whether this is just noise or an actual signal (except for the case of "E", which does seem like a genuine outlier).
I thought that this might be because "E" is so common that its inclusion leads to puzzles with too many solutions (a similar problem to "S"). To test this, the bar chart below shows the mean number of solutions in puzzles containing each letter:

Including certain common letters like "E", "D", and "R" seems to significantly increase the number of solutions, which might explain why those letters are underrepresented in published puzzles. However, "T" and "A" have similar mean solution counts without being underrepresented, so I'm not sure this fully explains it.
Highest Scoring Solutions
This table shows the highest scoring solutions ever used in puzzles accepted by The New York Times:
